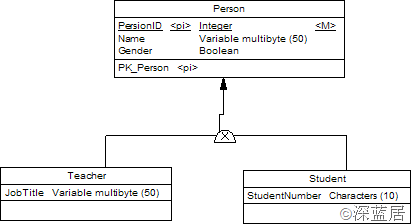
不建立父对象,将父对象的所有属性转移到子对象中,为每个子对象建立对于的表。如果使用这种方法,那么就只需要建立Teacher表和Student表,不需要Person表,在PowerDesigner中,双击继承节点,打开属性窗口,取消“Generate Parent”选项,选中“Generate children”并选择“Inherit all attributes”,如图所示:
Given an array of integers, find out whether there are two distinct indices i and j in the array such that the absolute difference between nums[i] and nums[j] is at most t and the absolute difference between i and j is at most k.
Example 1:
Input: nums = [1,2,3,1], k = 3, t = 0 Output: true Example 2:
Input: nums = [1,0,1,1], k = 1, t = 2 Output: true Example 3:
Input: nums = [1,5,9,1,5,9], k = 2, t = 3 Output: false
publicintdiv(int a, int b){ int x = isNeg(a)?negNum(a):a; int y = isNeg(b)?negNum(b):b; int res = 0; for(int i=31; i > -1; i= minus(i, 1)){ if((x>>i)>=y){ res |= (1<<i); x = minus(x, y<<i); } } return isNeg(a) ^ isNeg(b)?negNum(res):res; }
<sqlid="base_user"> p.*, u.id as u_id, u.username, u.password </sql>
<selectid="findByUserId"resultMap="projectMap"> select <includerefid="base_user"/> from project as p,user as u <where> p.user_id = #{userId} and u.id = #{userId} </where> </select> </mapper>
延迟加载的原理的是调用的时候触发加载,而不是在初始化的时候就加载信息。比如调用 a. getB(). getName(),这个时候发现 a. getB() 的值为 null,此时会单独触发事先保存好的关联 B 对象的 SQL,先查询出来 B,然后再调用 a. setB(b),而这时候再调用 a. getB(). getName() 就有值了,这就是延迟加载的基本原理。其本质是将整个查询的结果包装成一个代理,当要进行属性加载时,调用其被代理的一些方法,再从数据库中查 MyBatis 支持延迟加载,设置 lazyLoadingEnabled=true 即可(全局懒加载)。或者单独属性的懒加载(fetchType=lazy)
注意!如果在application.properties中指定了配置文件,那就不能再在application.properties中设置任何mybatis的配置, 也就是不能再设置任何以 “mybatis.configuration.XXX” 开头的属性 否则会报错: Property'configuration' and'configLocation' can not specified with together
Could not write JSON: No serializer found for class org.apache.ibatis.executor.loader.javassist.JavassistProxyFactory$EnhancedResultObjectProxyImpl and no properties discovered to create BeanSerializer (to avoid exception, disable SerializationFeature.FAIL_ON_EMPTY_BEANS);